
Abstract
이상탐지 분야에서 오랫동안 사용되왔던 알고리즘인 SVDD (Support Vector Data Description)를 patch-based 기반으로 바꾼 것.
Introuduction
이상탐지 분야에서 전통적으로 kernel function을 사용한 OC-SVM, SVDD와 같은 방식들이 있었는데 이전 연구 중 하나인 Deep SVDD는 neural network를 사용해 data-dependent한 표현을 뽑아냈다.
Patch SVDD는 Deep SVDD를 patch-wise 방식으로 바꾼 것이고 patch들의 높은 분산과 self-supervised 학습 방식에 기인해서 의미 있는 결과물을 만들었다.
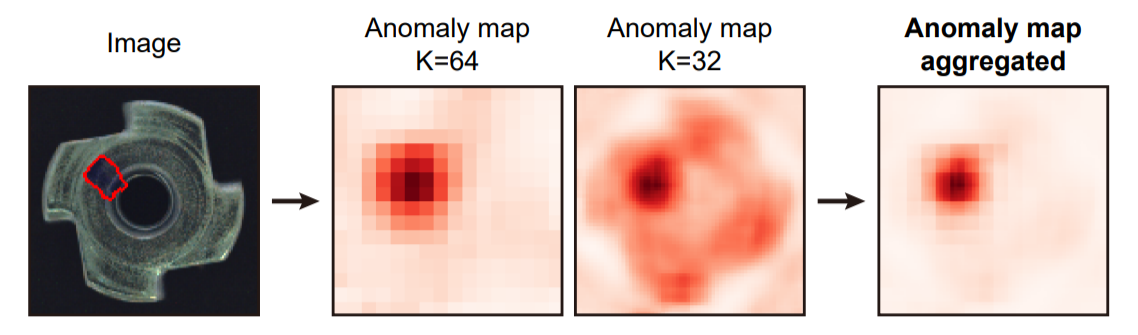
아래 그림은 Patch SVDD 모델을 통해서 나온 이미지 내에서 이상치 부분을 나타내는 것인데 multi-scale로 검출 결과를 뽑아내고 이를 결합해 이상이 있는 부분만 pinpoint 할 수 있게 된다.

Methods
Patch-wise Deep SVDD
Deep SVDD는 구의 중심과 encoder를 통해 나온 feature vector 사이의 거리를 최소화 하는 방향으로 학습한다.
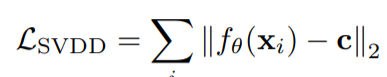
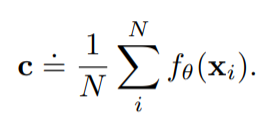
Patch SVDD에서는 image가 아닌 각각의 patch를 encoding 한다. patch encoder $ f_{\theta}$는 image 대신 patch $ \mathbf{p} $ 를 가지고 훈련하게 된다. complextiy가 높은 이미지(아래 이미지에서 오른쪽의 경우)에 대해서 성능이 잘 안나오는 경향이 있는데 이는 patch가 high intra-class variation을 갖기 때문이다. (dissimilar한 patch들을 하나의 center로 mapping 하려 했기 때문)
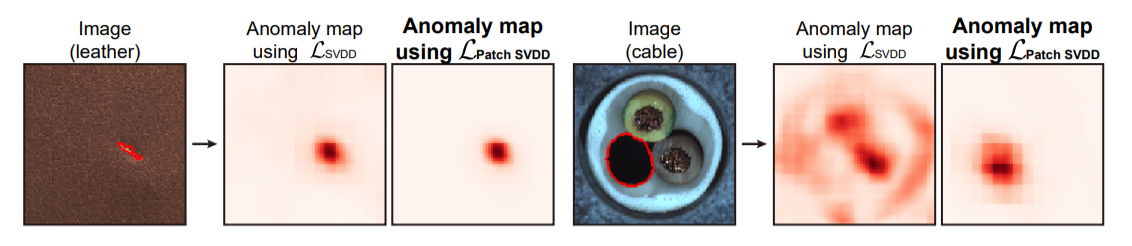
결론적으로, 모든 dissimilar한 patch들을 하나의 중심(center)으로 mapping을 하게 되면 patch들의 표현력을 저하시키게 된다. 대신에, 의미적으로 비슷한 patch들을 수집하도록 encoder를 학습시킨다. 의미적으로 비슷한 patch는 공간적으로 근접한 patch에서 찾는다.
encoder는 다음과 같은 loss를 최소화하는 방향으로 학습한다.
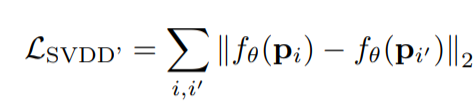
여기서 $\mathbf{p}_{i^{\prime}}$는 $\mathbf{p}_{i}$의 근접한 patch이다.
Self-supervised learning
기존 연구들을 통해서 self-supervised learning으로 학습된 encoder는 downstream task를 위한 유용한 feature를 뽑아내는데 도움이 된다고 밝혀져 있다. 따라서, 두 개의 patch의 상대적인 position을 예측하는 task를 잘 수행하게 되면 그 encoder는 위치를 예측하는데 있어서 유용한 feature를 생성함을 암시한다.
먼저 2개의 patch를 뽑는 방법은 하나의 patch $\mathbf{p}_{1}$가 있을 떄 3x3 grid의 8개의 이웃 patch 중에서 하나를 뽑는다.($\mathbf{p}_{2}$). classifier ${C}_{\theta}$는 아래 loss를 통해 상대적인 위치를 학습하게 된다.
patch size는 encoder의 receptive file와 같게 하고 classifier가 RGB 채널만 보고 쉽게 예측할 수 없도록 RBG 채널을 랜덤하게 섞는다.

최종적으로, encoder는 2개 loss의 combination으로 학습된다.


Hierarchical encoding
Anomaly의 사이즈는 다양하기 때문에 다양한 receptive field를 갖는 여러 개의 encoder를 학습시키는 것이 도움 된다.
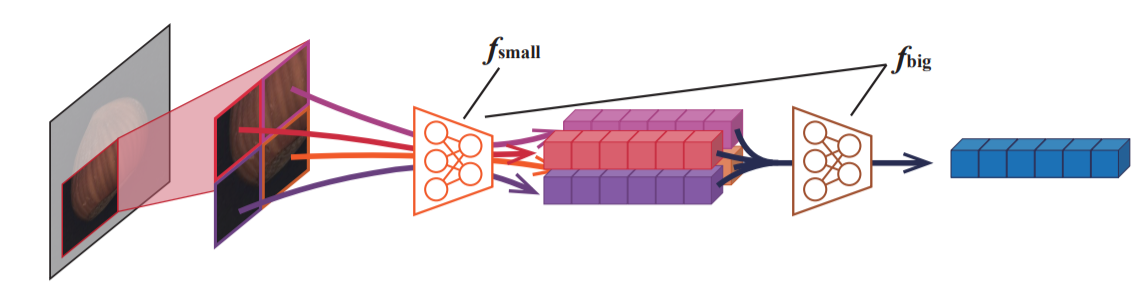

input patch $\mathbf{p}$는 2x2 grid로 나눠지고 $\mathbf{f}_{small}$ encoder를 통해 나온 4개의 features들은 합쳐져 $\mathbf{p}$의 feature를 이루게 된다. small과 big의 receptive field 사이즈는 각각 32, 64로 설정했다.
Generating anomlay maps
Encoder를 통해 나온 representation을 가지고 anomaly 유무를 판단하게 된다.
절차는 다음과 같다.
1) normal train patch에서 나온 모든 representation을 저장한다.
2) query image $\mathbf{x}$가 주어지면, 모든 patch에 대해서 L2 distnace를 기준으로 가장 가까운 normal patch를 찾는다. 그 후, patch에 대한 anoamly score 식은 아래와 같다.
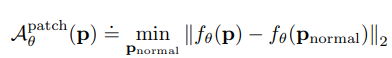
patch-wise로 구해진 anomaly score는 pixel 단위로 재분배가 되는데 각각의 pixel은 그 pixel이 포함된 모든 patch로부터의 average anomaly score을 받게 된다.
Hierarchical encoding에서 설명했듯이 multiple encoder 구조이므로 multiple anomaly map을 산출하게 된다. 이를 $\mathcal{M}_{\text {multi }} \doteq \mathcal{M}_{\text {small }} \odot \mathcal{M}_{\text {big }}$ 처럼 element-wise multiplication을 하여 최종 anomaly map을 구한다.
또한, image에 대한 anomaly score는 anomaly map 에서의 anomaly score의 max 값을 취한다. $\mathcal{A}_{\theta}^{\text {image }}(\mathbf{x}) \doteq \max _{i, j} \mathcal{M}_{\text {multi }}(\mathbf{x})_{i j}$
Results and Discussion
t-SNE visualization

regularly positioned 클래스들(object class)은 비슷한 색깔과 사이즈의 point들은 비슷한 위치에 t-SNE가 찍힌다. (sementically similiar). 이는 같은 position에 있는 patch들은 비슷한 content를 갖는다는 것을 의미한다. ex) cable
반면, texture 클래스들은 patch의 위치가 큰 의미를 갖지 않는다. ex) leather
Effect of self-supervised learning
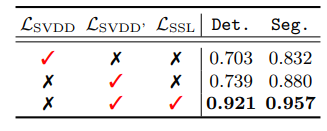
patch svdd는 2개의 loss를 사용한다고 말했다.
1) $\mathcal{L}_{\text {SVDD' }}$ ($\mathcal{L}_{\text {SVDD}}$를 개선 시킨 것)
2) $\mathcal{L}_{\text {SSL}}$
제안된 loss term의 효과는 class마다 상이했으며 특히 texture class에서는 loss의 선택에 덜 민감했다. 하지만 object class에서는 $\mathcal{L}_{\text {SSL}}$ loss term으로부터 상당한 이득을 보았다.
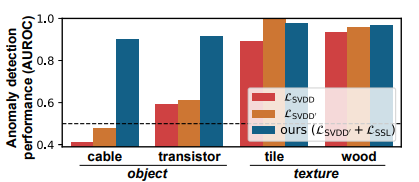
이 이유에 대해서 설명하기 위해 저자는 object class에 대한 t-SNE를 그려보았다.
아래는 object class 중 하나인 transistor class 경우의 multiple train images를 plotting한 t-SNE이다.

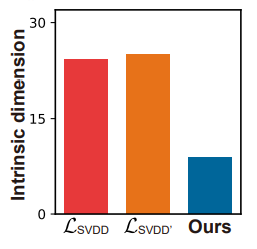
$\mathcal{L}_{\text {SVDD' }}$, ($\mathcal{L}_{\text {SVDD}}$는 uni-modal cluster를 형성하지 $\mathcal{L}_{\text {SSL}}$는 color와 size에 따른 multi-modal cluster를 형성한다.
object class는 각각의 patch가 높은 intra-class variation을 갖고 있는데 dissimilar한 의미를 갖는 patch들을 잘 구분해 냈다.
$\mathcal{L}_{\text {SSL}}$의 효과를 증명하기 위해 intrinsic dimension(ID)라는 개념을 사용하였는데 이것은 point를 표현하기 위해 필요한 minimal number of coordinates로 정의된다. larger ID는 point가 모든 방향으로 spread 된 것을 의미하고 smaller ID는 point가 low-dimensinal manifold에 높은 seperability를 갖는다는 것을 의미한다.
Hierarchical encoding
서로 다른 scale의 encoder에서 나온 anomaly map은 상호보완적인 역할을 한다. large receptive field를 가진 encoder는 coarsely(거친)하게 결점 부분을 찾고, smaller receptive field는 refine(정제)하는 역할을 한다.
Hyperparameters
$\lambda$의 최적값은 class에 따라서 달라진다.
object class에서는 small $\lambda$, texture class에서는 larger $\lambda$로 설정한 경우 좋은 검출 성능을 보인다. 이 현상이 발생하는 이유는 앞서 설명한 것과 같이 self-supervised learning은 patch들이 high intra-class variation(object class인 경우)을 갖는 경우에 도움이 되기 때문이다.
Random encoder
랜덤하게 초기화된 encoder도 image retrieval에서 좋은 성능을 보인다는 연구가 있다. 어떤 이미지가 있을 때, random feature space에서의 nearest image들은 인간에게 비슷하게 보인다는 것이다. 위 연구에 영감을 받아 랜덤한 encoder을 썻을 때의 성능을 테스트 해보았다. 특정 class에 대해서는 random encoder가 normal과 abnormal image를 분류하는데 좋은 결과를 보였다. 이 결과를 보인 이유에 대해서 다음과 같이 증명했다. (encoder는 weight W와 bias b로 이루어진 1개의 convolution layer로만 이루어졌다고 가정, *=convolution operation)
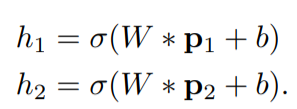
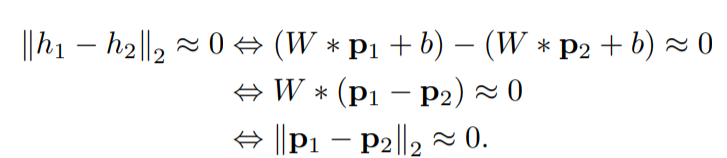
nearest patch들은 비슷하기 때문에 feature space에서도 비슷하게 된다는게 위 식에서 증명된다.
Conclusion
Deep SVDD와 다르게 patch level을 사용하여 결점을 localize할 수 있는 방법론이다. 더욱이 self-supervised learning을 사용하여 검출 성능을 더 높였다.
또한, raw image space에서 비슷한 위치의 patch는 random feature space에서도 거리가 가깝게 되므로 random features는 정상과 비정상을 구분하는 역할을 할 수 있다.
'Paper > Anomaly detection' 카테고리의 다른 글
| [논문 리뷰] Towards Total Recall in Industrial Anomaly Detection (0) | 2022.02.22 |
|---|---|
| DFR: Deep Feature Reconstruction for Unsupervised Anomaly Segmentation (0) | 2021.07.19 |
| [Explainable Deep One-Class Classification] 논문 정리 (0) | 2021.06.17 |