![[Explainable Deep One-Class Classification] 논문 정리](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FbbtiWE%2Fbtq7yBzdkeT%2FAAAAAAAAAAAAAAAAAAAAAJ7xoRPanNk56XwZ0rD9LVlsHqKWTop61UH0ZSOAVey8%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1777561199%26allow_ip%3D%26allow_referer%3D%26signature%3DzfASwnuNiemTrHEzrq6Ch39Kt5E%253D)
Abstract
One-class classification은 정상 샘플들의 분포를 학습해서 비정상 샘플들이 들어오면 학습된 분포 밖으로 맵핑 되도록 하는 것이 목적이다.
분포를 학습하기 위해서 highly non-linear 변환이 발생하는데 이로 인해서 이미지의 어느 부분이 이상이라고 해석하는 것이 어려워진다.
본 논문에서 제안하는 Fully Convolutional Data Description (FCDD) 모델을 사용하면 좋은 이상 검출 성능 뿐만 아니라 합리적인 설명력을 갖게 된다.
또한, 학습 과정에서 소수의 (5개 미만) 비정상 데이터를 결합하여 성능을 상당히 향상시킬 수 있다.
마지막으로, Deep one-class classification 모델이 워터마크와 같은 supurious image features에 취약하다는 것을 설명한다.
Introduction
최근들어 deep anomaly detection 많은 연구들이 진행되고 있지만 설명력(explanation)이 있는 모델을 만드는 것에는 많은 연구가 이뤄지지 않았다. 특히, 산업 현장에서는 안전 요구 사항을 만족, 불공정한 사회적 편견 피하기, 전문가의 의사결정에 도움 등에 explanations이 필요하다.
FCDD는 Deep Support Vector Data Description (DSVDD)에 기반한 모델이다. FCDD는 transformed samples가 downsampled anomaly heatmap에 상응하도록 만든다. Heatmap에서 center와 멀리 떨어져 있는 pixel을 anomalous regions라고 판단한다. FCDD는 convolutional과 pooling 층만 사용하여 output pixel의 receptive field를 제한한다.
Explainable Deep One-Class Classification

Deep One-Class Classification 이란?
정상 샘플들을 neural network를 이용해 center c 근처로 맵핑되도록 학습한다. 여기서는 DSVDD의 semi-supervised 버전인 Hypersphere Classifier (HSC)를 사용한다.
HSC의 objective는 다음과 같다.
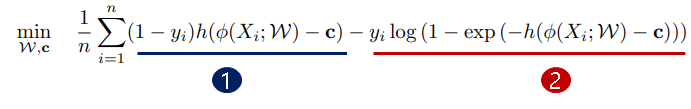
1은 정상 데이터일 때 c와 가깝도록 학습하는 term
2는 비정상 데이터일 때 c와 멀어지도록 학습하는 term

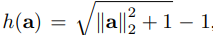
y = 0은 정상 샘플, y = 1은 비정상 샘플을 나타낸다.
HSC loss는 ϕ가 정생 샘플은 c 근처로 맵핑하고 비정상 샘플은 c에서 벗어나도록 한다.
c는 network의 마지막 층의 bias로 설정한다.
Fully Convolution Architecture (FCN)
Spatial information을 보존하기 위해서 이와 같은 구조를 사용한다.
Convolutional layer의 특징은 output의 각각의 pixel은 input의 small region에 의존한다. (output pixel's recpetive field)
Fully convolutional network는 convolutional과 pooling layer만 사용하여 이미지를 matrix로 맵핑한다.

Fully Convolutional Data Description (FCDD)
앞서 설명한 HSC와 FCN을 결합하여 공간적 정보를 보존하면서 이상탐지를 하고 downsampled anomaly heatmap을 구할 수 있는 모델이 FCDD이다.
FCDD는 정상과 비정상 샘플 모두를 이용하여 학습된다. 비정상 샘플을 소량 사용해서 학습을 하는 것을 Outlier Exposure (OE)라고 하는데 보통 비정상 샘플은 test 시에 들어오는 데이터와 비슷한 것으로 사용하면 좋다. 설사 알고 있는 비정상 샘플이 없다 하더라도 syntehtic anomalies를 생성하여 사용할 수 있다.
FCDD objective는 FCN에서 나오는 행렬에 Huber loss를 적용한다. 모든 operation은 element-wise로 이뤄진다.


$\parallel A(X_i)\parallel$ - 정상 샘플인 경우에는 줄이고 비정상 샘플인 경우에는 최대화 되도록 학습
따라서 $\parallel A(X_i)\parallel$ 를 anomaly score로 사용할 수 있다.
A(X)는 원래 이미지의 공간적 정보를 보존하고 있다. A(X) 자체를 low-resolution heatmap으로 사용할 수 있지만 원래 이미지 사이즈와 같은 heatmap을 갖도록 하는게 바람직하다. 이를 위해서는 receptive field의 특성을 이용한 upsampling이 필요하다.
Heatmap Upsampling
일반적으로 비정상 샘플들의 비정상 pixel annotaion 데이터가 없기 때문에 지도 학습으로 upsampling을 할 수는 없다.
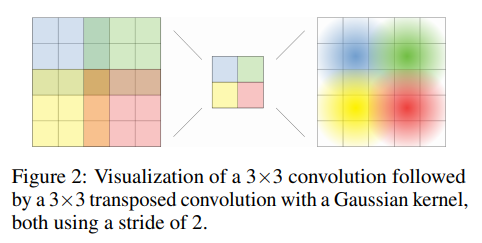
A(X) 각각의 픽셀은 receptive field의 중앙부에 상응하는 unique한 input pixel과 상응한다. receptive field의 output pixel에 대한 영향은 receptive field의 중앙부에서 멀어질수록 가우시안 형태로 감소하는 것이 관측되었다고 한다. 이 사실을 이용해 fixed 가우시안 커널을 갖는 strided transposed convolution을 사용해 A(X)를 upsampling 한다.
strided transposed convolution 이란?
...
Upsampling 알고리즘은 다음과 같다.

Experiments
Area Under the ROC Curve(AUC)를 이용한 quantitative 분석과 anomaly heatmap을 가지고 qualitative 분석도 하였다.
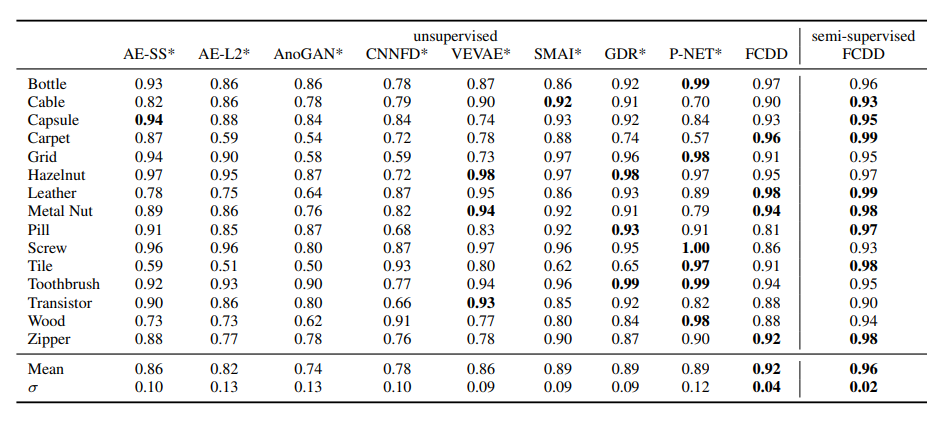
Quantitative Results
FCDD와 비교할 모델로는
1. known anomalies을 사용하지 않음
autoencoder(AE), DSVDD, Geometric Transformation based AD (GEO), variant of GEO (GEO+)
2. OE 사용
Focal loss classifier, GEO+, Deep SAD, hsc
모든 클래스에 대한 AUC 평균값을 사용

설명력을 위해 구조를 제한했음에도 SOTA와 성능이 비슷하고 AE보다는 성능이 좋게 나온다.
Qualitative Results

Fashion-MNNIST Data
정상 데이터 클래스는 바지정장이고 (B), (C)는 OE 데이터로 각각 CIFAR-100, EMNIST를 사용했다.
왼쪽에서 오른쪽 컬럼으로 갈수록 anomaly score가 커진다.
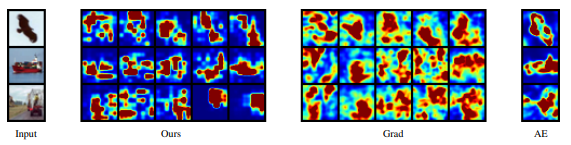
CIFAR-10 Data
비행기를 정상 데이터 클래스로 학습했다.
Ours, Grad는 왼쪽부터 2, 8, 128, 2048, full OE를 사용한 경우이다.
OE 샘플이 늘어날수록 FCDD는 이미지 속의 primary object에 좀 더 집중을 하는 경향이 있다.
Explaining Defects In Manufacturing
제조 도메인 데이터 셋인 MVTec-AD은 이미지의 어느 위치에 이상치가 있는지를 나타내는 값을 가지고 있다.
이것을 이용하여 모델이 어느정도 설명력을 갖는지 표현하는 "explanation" AUC 스코어를 계산할 수 있다.
Synthetic Anomalies
ImageNet과 같은 데이터를 OE로 사용하기에는 MVTec-AD 데이터셋의 결함은 매우 미묘하여 크게 도움이 되지 않는다.
따라서 "confetti noise" 노이즈 모델을 사용하여 이미지에 색깔이 있는 결점을 추가하여 synthetic anomailes를 만든다.

Semi-Supervised FCDD
FCDD의 장점은 비정상 데이터를 훈련할 때 사용하여 성능 향상을 이끌 수 있다는 것이다.
각 클래스에서 비정상 데이터를 하나씩 뽑아서 훈련 데이터에 넣는다. (총 3~8개)
특히 MVTEC에서는 ground-truth anomaly heatmap도 활용할 수 있다.

m= h*w (number of pixels)
픽셀별로 0(정상) 혹은 1(비정상) 값을 갖는다.
The Clever Hans Effect
원하는 답에 대한 단서를 제공하는 것을 "Clever Hans" 효과라고 한다. PASCAL VOC 이미지 데이터의 1/5 상당의 말 이미지 경우에 좌측 하단에 워터마크가 있는데 워터마크가 지워지면 말이라고 인식을 하지 못하게 된다.
말을 비정상 클래스 ImageNet을 정상 클래스로 두고 테스트 한 결과

(a) - 왼쪽에서 오른쪽으로 갈 수록 비정상 샘플이라고 판단
(b) - clever hans effect가 있음을 보여준다. (워터마크 쪽에 높은 이상치)
말 object 자체에는 높은 anomaly score가 나오지 않았음. 비정상 데이터 셋에서 말이 bar나 fence를 넘는 사진이 많아서 이 부분이 score가 높게 나왔고 모델은 말이 suprious features 라는 것을 학습할 때 알 방법이 없어서 그렇다.
그렇지만 FCDD는 블랙박스 모델과 달리 heatmap을 통해서 이런 undeseriable 현상들을 파악할 수 있다.
'Paper > Anomaly detection' 카테고리의 다른 글
| [논문 리뷰] Towards Total Recall in Industrial Anomaly Detection (0) | 2022.02.22 |
|---|---|
| Patch SVDD (0) | 2021.07.22 |
| DFR: Deep Feature Reconstruction for Unsupervised Anomaly Segmentation (0) | 2021.07.19 |